0手续费交易对值得被重视
6月,币安推出了几个0手续费交易对,紧接着Dydx交易所也跟进了。

dydx 交易所, 用户交易额的不同,手续费也不同
和币安不同,币安仅仅减免少量几个交易对的手续费。 DYDX则根据用户的交易额的不同,手续费可能是 0% ~ 0.1% 不等。
- 月交易量小于10w U 或者 大于 5000w U的用户是免手续费的;
- 介于10w ~ 5000w 的用户是手续费的主要贡献者。
真的有点类似我们社会的中产阶级,穷人阶级太穷了无法收割,富豪阶级富可敌国,收割不了。
那么0手续费交易(对)值得薅吗?
我们做一下实验。
手续费差之毫厘,收益失之千里
下面是同一个由AI驱动的策略。
按万分之0.5 (0.005%) 手续费计算, 也就是几乎忽略手续费,2022年初至八月底 获得了679.48倍收益 (是679.48倍,不是679.48%,没错!)。

下图按万二五(0.025%)手续费计算,收益只剩 7.03 倍了。

下图按万分之5(0.05%)手续费计算,收益是负的! -0.28倍!
但是从下方的第二个子图的蓝色点 vs 红色点可以看出,盈利的交易依然多于亏损的交易,只是获利不足以覆盖手续费开支而已。

越是高频的交易策略,对手续费越是敏感
笔者做了一下实验,发现最小K线用到2分钟图(但是不意味着只使用2分钟K线,可能同时也使用了6/8/12/20/25/40/50分钟图,稍后解释)的策略,按一开一平各万分之五(0.05%)手续费计算,2022年至今依然获得 429倍的收益, 但手续费消耗也极大,也就是说,每获得100W收益,就给交易所贡献了大约30W手续费。
实验1
最小周期K线使用15分钟图的策略,2022年获利能达到 14倍, 但是手续费/利润比达到0.1662, 也就是说,每获得100W收益,就给交易所贡献了大约16W手续费。
| item | value |
|---|---|
| 回测天数 | 2022-01-01 ~ 2022-08-22, 一共经历234天 |
| 最小K线周期 | 15分钟 |
| 总计K线数量 | 22369 |
| 有交易的K线数量 | 1570 |
| 平均每日开平仓次数 | 3.3547 |
| 盈利次数 | 485 |
| 亏损次数 | 300 |
| 胜率 | 0.6178 |
| 盈亏比 | 4.66725 |
| 最大回撤 | 2022-06-15~2022-06-17 -4.39 % |
| 初始资金 | 10000 |
| 期末收益 | 143915.3983 |
| 手续费 (0.05%) | 23931.5461 |
| 手续费/利润比 | 0.1662 |
| 详尽performance report | 点此查看详尽的performance report |
实验2: 高盈亏比能缓冲手续费开支
最小周期K线使用5分钟图的策略,2022年获利能达到122.8倍, 手续费/利润比达到 0.111, 也就是说,每获得100W收益,就给交易所贡献了大约11W手续费。看起来比实验1更好,但是这个策略的盈亏比可是实验1的3.5倍。
| item | value |
|---|---|
| 回测天数 | 2022-01-01 ~ 2022-08-22, 一共经历234天 |
| 最小K线周期 | 5分钟 |
| 总计K线数量 | 67105 |
| 有交易的K线数量 | 1878 |
| 平均每日开平仓次数 | 4.0128 |
| 盈利次数 | 718 |
| 亏损次数 | 221 |
| 胜率 | 0.7646 |
| 盈亏比 | 14.5567 |
| 最大回撤 | 2022-05-12 ~2022-05-12 -4.33 % |
| 初始资金 | 10000 |
| 期末收益 | 1228343.2434 |
| 手续费(0.05%) | 136474.0234 |
| 手续费/利润比 | 0.111 |
| 详尽performance report | 点此查看详尽的performance report |
实验3
最小周期K线使用2分钟图的策略,2022年获利能达到428.4倍,手续费/利润比达到 0.298, 也就是说,每获得100W收益,就给交易所贡献了大约29.8W手续费
| item | value |
|---|---|
| 回测天数 | 2022-01-01 ~ 2022-08-22, 一共经历234天 |
| 最小K线周期 | 2分钟 |
| 总计K线数量 | 167761 |
| 有交易的K线数量 | 7746 |
| 平均每日开平仓次数 | 16.5512 |
| 盈利次数 | 2342 |
| 亏损次数 | 1531 |
| 胜率 | 0.6046 |
| 盈亏比 | 5.0219 |
| 最大回撤 | 2022-05-12~2022-05-12 -5.92 % |
| 初始资金 | 10000 |
| 期末收益 | 4284453.7637 |
| 手续费 (0.05%) | 1280223.3087 |
| 手续费/利润比 | 0.29880 |
| 详尽performance report | 点此查看详尽的performance report |
上面均是没有使用杠杆的结果。 每日的交易次数有点多,因为系统会合成6/8/12/20/25/40/50分钟等不常见的K线,并抓住其中的交易信号。
题外话
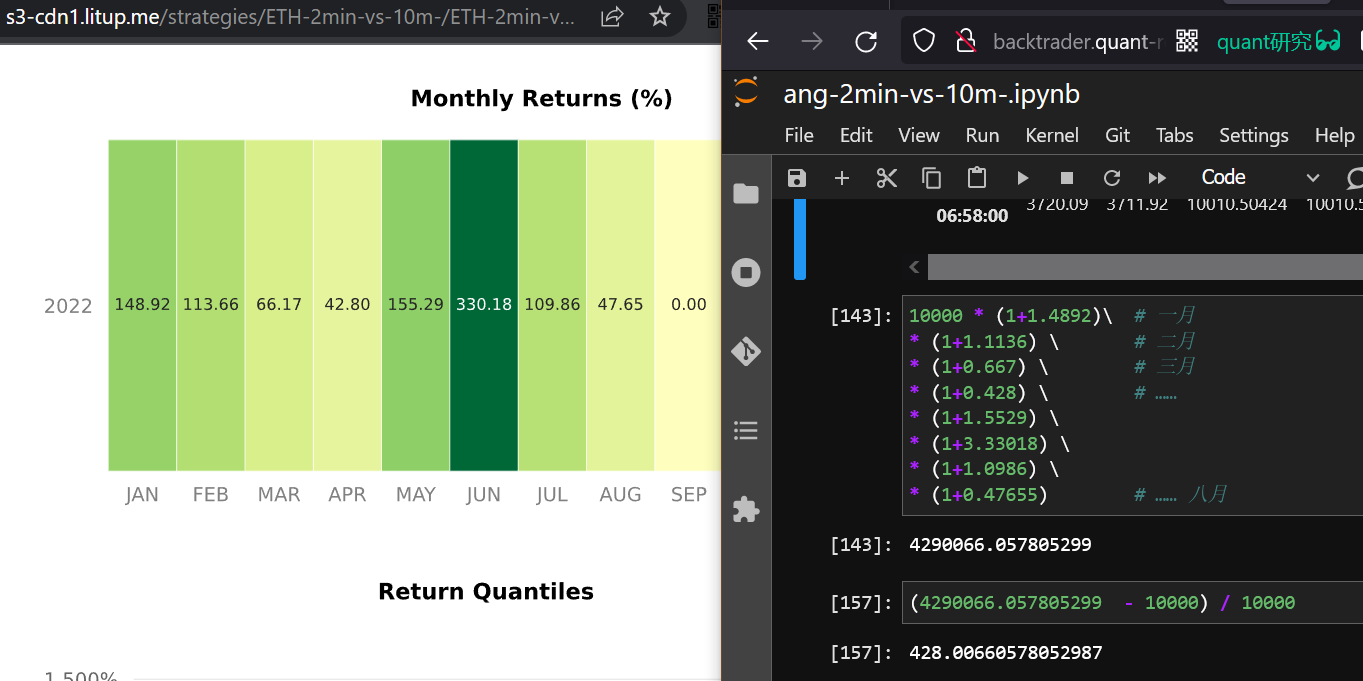 没什么好惊奇和质疑的,刚才428倍收益的策略,分散到每一个月份,也就42%~330%而已
没什么好惊奇和质疑的,刚才428倍收益的策略,分散到每一个月份,也就42%~330%而已
上面的实验中,有些策略不到1年就几百倍的收益,系统算错了吧! 还是用了什么黑科技?
我第一感觉也怀疑系统算错了。
然后我用了PyFolio 、 QuantStats 和 Backstrader自带的analyzer分别做了业绩分析,结果显示一致的。
依然担心它们全部都错了,就又用pandas分析和统计了原始的交割单,再抽查了部分交割单的盈亏和手续费计算,结果显示依然是一致的。
 原始交割单
原始交割单
原始的交割单有备份,哪位读者朋友有兴趣再次分析一下, 可以加入 这个Slack Channel 索取, 如果加不了请 点此Telegram联系博主。
 欢迎加入“ML与量化”Slack Channel一起探讨学习
欢迎加入“ML与量化”Slack Channel一起探讨学习
上面是开发者/研究人员的Channel, 不想参与研究,只想围观研究成果的读者朋友请加 https://litupme.slack.com/archives/C042YH1C945
至于有没有使用什么黑科技,可以简单的总结为:
如果这部分没看懂,可以先读下方FAQ,然后再回头看
- 1.时序预测模型提供了60%左右的准确率 <- 很平凡对吧?
- 2.仓位优化模型加重了获利较好的交易的仓位,减少了获利一般的交易的仓位,阻止了亏损或者不盈不亏的交易。
- 3.风控模型使用和1类似的预测技术,在暴风雨来临之前就“只平不开”,或者提前退场避险,把最大回撤压到极低。
- 4.按需合成 6/8/12/20/25/40/50分钟的K线图,并监控其中的交易信号提供了更多的交易机会,日均交易次数有时可达16次/日。
更详尽的信息请认真看下方FAQ
Faq
下面部分有很多AI领域的专业术语,没有相关基础的读者可以先看看“AI知识导读”
AI知识导读(点击展开)
>> 你知道吗? 在暴风雨来临之前,你会看到一些迹象:天空乌云密布,狂风把树叶、沙尘和垃圾袋刮得四处乱飞 等等迹象。在地球上待久了的居民都能预感暴风雨来临。
> 金融市场的风暴来临之前,也是有一些迹象的,在金融圈待久了的人能够预感风暴的来临。
>> 以前,天气预告是靠气象学家人工分析的, 要看卫星云图和各种传感器的数据,看完这个城市,看那个城市,非常辛苦。气象学家要经过多年的学习和实战才比较准确。
> 以前,金融投资是靠分析师/基金经理人工分析的,要看图表和各种财报数据,看完这家公司,看那家公司,非常辛苦。 分析师/基金经理要经过多年的学习和实战才能上战场。
>> 现在,天气预告是由AI模型分析和预测的。只要GPU够强大AI模型可以一夜之间吃掉过往几年的气象数据,并从中学会天气预测。
> 现在,金融投资是由AI模型分析和执行的,只要GPU够强大AI模型可以一夜之间吃掉过往几年行情数据,并学会……
—— —— —— —— —— —— —— ——
假定我们有一个预测天气的AI模型,我们丢几年的历史天气数据给它学习,那么这几年的数据叫做训练集, 数据中的 温度、湿度、风向、风速等有效成分称之为特征。 模型投入使用之前,我们先给它几个月的数据(且这些数据是训练集里面没有的,它从来没有见过的)让它试试预测得准确不准确,那么这部分数据叫做测试集,测试集和训练集必须没有交集。 “预测”更专业的叫法也称作 推导。
假定这个模型是预测 明后天下雨还是不下雨的,这个模型是二分类模型,它推导的结果只有2个:下雨、不下雨。
假定这个模型是预测明天 不下雨、小雨、中雨、大雨、暴雨的, …… 它是 多分类 模型。经常用于做分类任务的神经网络有 DNN。
假定这个模型是预测明天的气温的——一个个具体的数值的, 它是个线性回归模型。 因为气温在每个时间点都有一个值(类似股价),这个推导任务也称之为 时序预测 。 经常用于时序预测的神经网络有 LSTM、seq2seq、 transformer等。
假定这个模型同时推导出 明天有没有 小雨/中雨/大雨/暴雨、明天气温、风速、风向、湿度、紫外线强度等, 可以用seq2seq 来实现。
上面这些模型都需要人类整理和标注许多数据喂给它学习,还有许多调参等人工环节,这个过程叫做 有监督学习 。
假定把1个AI自动驾驶车辆扔到路上让它乱撞,撞死算了,重头再来, 当它撞了数不清次之后就自己学会开车了, 这叫做 无监督学习 。
—— —— —— —— FAQ: —— —— —— ——
-
策略是在什么周期的K线上操作的?
答:全部周期。传统的交易会在 1分钟、5分钟、10分钟、30分钟、1/2/4/12小时等线图上操作。
而这个策略会K线图重采样为 2/3/4/6/7/8/9/12/16 …… 40/50分钟图,并抓住其中每一个周期的交易机会。实验证明:单个标的在多个周期的交易机会要比 多个标的在单个 timeframe K线图上的交易机会 要多得多,可能是因为整个币圈的98%的比都是具有协同性(高度相关的),大饼在15分钟图上没有交易机会时,遍历整个市场,通常也没有。
但可能不会同时使用 51分钟、52分钟、53分钟 这种图, 因为他们太过于类似了,浪费计算资源。 -
策略在满足什么条件下开仓和平仓呢?
答:并不能用传统的技术指标术语去描述,也不能用硬编程或者数学公式去界定,就像你可以写出程序代码或者数学公式分辨胖子和瘦子,但是“美女”和“非美女”却很难用程序代码或者数学公式来分组。AI模型则可以给颜值打分,前提是,你喂给它足够多的美女图片和得分。
不否认训练集中也有一些流行的技术指标和新创的指标作为特征,但目前还没有用feature selection去衡量其对模型推导结果的帮助。 -
训练集都包括哪些数据?
答:单个交易提供的OHLCV数据、多个交易所提供的volume数据、ETH/EVM运作产生的数据(并非由交易所提供)、Gan模型生成的一些未来仿真数据。数据多多益善,就像一个预测天气的模型,最开始可能只有 过去和当前的温度、湿度、风向、风速、紫外线强度、pm2.5等,现在把太阳黑子活跃程度 的数据也扔进去,说不定天气和太阳黑子真的有关系,模型就能获得进步,当然如果他们俩没有啥关联,最坏的结果也只是多耗点CPU 算力而已。 -
用了多长时间的数据作为训练集? 测试集呢? 发生数据漂移时是怎么处理的?
答:非严格来讲最初训练集数据只有2021年上半年的2-6个月的数据, 但是策略中使用的大部分模型是 online training 模型,意味着,当回测K线走到2022-02-22时,各个模型已经用2022-02-21以前的数据训练了自己; 当回测K线走到2022-02-23时,各个模型已经用2022-02-22前的数据训练了自己。和一些用了前两年的数据做训练和测试集,然后期望不用继续更新,就能在今年中表现卓越的模型还是不一样的。
如果数据只是缓慢地发生了concept drift,上面的机制会很快地学到新的概念;如果极短时间内发生了剧烈的domain drift,寄望于下方2个风控模型起作用。 -
这是CTA趋势策略还是均值回复策略?
答:不能用传统的目光去归类。这是1个AI驱动的策略,其中有一组时序预测模型负责预测未来几根K线的走势,如果模型推导出来的近期K线往某一个方向走的幅度和概率达到一定的标准(并且这次交易被另外一个多分类模型分到“盈利的”、“不盈不亏的”、“亏损的”中的第1种分类),系统则会顺势开仓。……更像CTA策略。 -
最大仓位是多少? 最大杠杆呢?
答:也是由AI决定的。 上面提到 “并且这次交易被另外一个多分类模型分到“盈利的”、“不盈不亏的”、“亏损的”中的第1种分类”只是为了简化易理解的解释,实际上 “盈利的” 这种类别中又分为 “盈利超过100%的”、“盈利50~100%的”、“盈利20~50%的”等等,假定一次交易在准备开仓时被这个分类模型分到比较靠前的类别,则仓位比较重,否则比较轻。杠杆是动态的,被限制为最高不超2倍。 -
最大回撤是多少? 有没有设定硬止损?
答:不超6%,没有设硬止损。 风控这块由3个模型起作用:
第1个是上面的多分类模型,假定一个交易在即将开仓的一瞬间被分类到 “不盈不亏的”或者“亏损的”,则仓位被调整为0。
第2个模型是一个非常保守的时序预测模型,利用了“狂风大雨来临前夕,总是会有一些征兆,在地球上生活久了的人都懂。金融风暴来临之前也会有征兆”的原理, 模型发现推导出的K线走势和真实走势不接近了,就知道自己不行了,“宁可错过,也不做错”,就知道该跑了。假如传统的乖离率像“假如3小时内平均降雨超过150mm,那么我们就终止运动会,回室内休息(但毕竟也被雨淋了3个小时)”, 那么时序预测模型更像“如果接下来的几个小时不再天晴,那么就不开运动会了”。 传统的指标计算止损法是滞后的,等待亏损发生了再去止损,预测模型努力去躲开风险大于收益的区域。
第3个模型是一个强化学习模型,目的是让1和2成为好搭档发挥到最优。
长按识别下方二维码可在浏览器中打开阅读。
